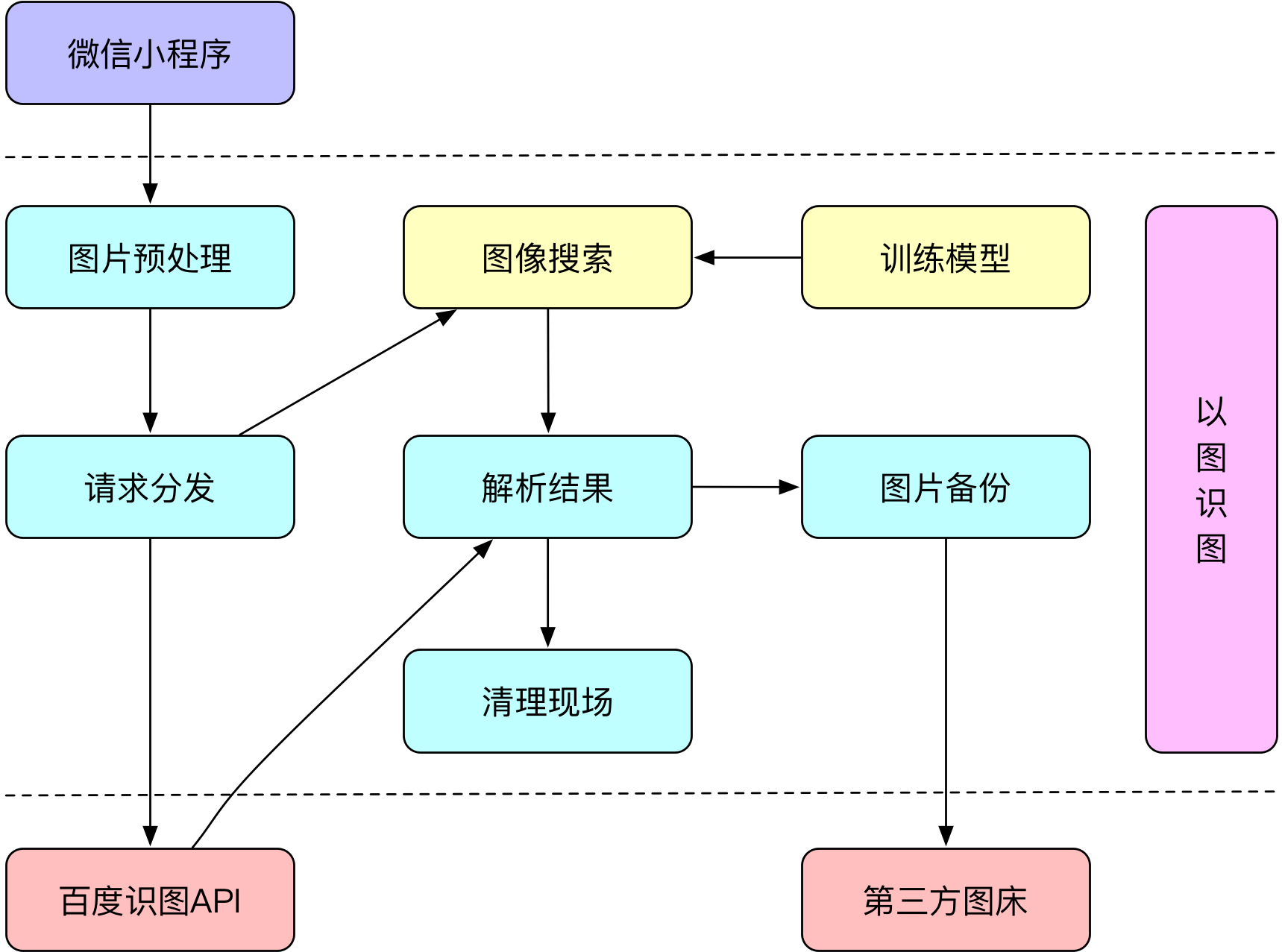
基于抓包获取的第三方识图API接口实现的以图识图有很大的风险,为了应对随时可能被修改的API以保证以图识图应用的高可用,对以图识图应用架构的健壮性提出了很高的要求,同时对多个第三方识图API的结果进行破解、解析、抽象都需要消耗大量的精力。此外,识别速度无法控制,识别率无法调优等这些都是我们需要解决的问题。解决方案有二,要么找到一个靠谱的第三方API,最好是能够根据自己的需求订制服务,要么就自己动手丰衣足食,搭建自有的图像识别系统,两种方案各有优劣。
目前找到比较靠谱的是百度识图服务,官方正在推各种图像识别服务,这与百度All in AI的战略是一致的。百度的植物识别API识别率还不错,但有每日500次的免费调用限制,付费服务还未开放,调用超限需要要额外申请配额。如果需要识别某特定应用领域的图像,可以将图片按照指定的格式打包给百度识图的产品经理,他们的工程师会帮助训练模型,自助训练管理服务还在开发中,目前代训练模型的服务还是免费的,百度的图像识别是搭建在其PaddlePaddle并行分布式深度学习平台之上的。当然这种方式可以帮助我们节省大量的开发维护成本,使得我们可以接入更稳定的AI服务,但这种方式也不是完美无缺的。首先,识别速度还有待提高,虽然从之前架构的20秒左右压缩到目前5秒左右出结果,为了更好的用户体验还需要更进一步压缩时间,即便图片经过压缩还是必须经历上传到自有服务器再到百度服务器再层层返回结果的过程,这无疑将增加图片在网络中的传输时间。其次,识别的过程对于我们来说是透明的,我们无法知道是否可以优化识别速度,我们也无法对识别率进行调优。另外,如果我们需要保证图片的私密性,给百度提供训练样本就不再可行了。
搭建自有的图像识别系统,优化识别速度和识别率的问题都会迎刃而解。也许之前这非常的困难,但随着机器学习技术的开源和成熟,我们也有了实现的可能性。TensorFlow是众多开源的深度学习库的佼佼者,当然还有pytorch、mxnet、caffe等。TensorFlow社区活跃文档齐全,还有Google的强大背书,选择TensorFlow还有一个很重要的原因是我可以用python训练模型,并用Java将结果无缝整合进应用中。图像识别系统搭建好之后我们还需要大量的图片样本来训练模型,至于图片来源可以把你能想到的所有招数都使出来吧,爬虫、搜索引擎、掏钱买。如果你的应用领域比较偏,图片掌握在某些专业研究机构手中,那么你可能必须掏钱买才行。这里还有一个小插曲,为了节约时间和精力一次搜集比较齐全且可靠的植物分类图片我尝试咨询了一家国字号研究所,但却被深深鄙视了「你买不起,一张图片60块」,且在对方获知了我要做一个植物识别类应用时居然说「你不要做了,因为百度等在做,我们也在做」。默默挂上电话后心想你们这帮人占着这么多资源做出目前这种识别效果还好意思要垄断,我只能呵呵了。断了念想只能另辟蹊径,其实各种图鉴、搜索引擎、论坛、贴吧都有大量的图片可以利用,只不过需要你有一定的专业领域知识才可以鉴别植物的物种,自己也养了不少种植物有了一定的区分能力。后来在搜集整理图片时发现不依赖于上述科研院所的图片我居然幸运的,不然花钱还被他们坑了,从他们官方网站上搜索到的图片质量真的很一般,很多都是爱好者拍摄上传的,不少物种图片张冠李戴,我不知道这样的图片如何通过审核被他们确认入库的,而百度等公司又没有植物领域的专家只能相信这些科研院所的图片数据,这就可以解释为什么他们有的物种识别率很低了。此外,植物识别是一个「closed world」的问题,就是说这个领域是有边界的,这次遭遇也让我更加坚定了做下去的决心,只有更专注才能做得更好。最终的识别结果是以概率的形式展现的,由于限定了样本图片的范围使得我们不会出现百度那样的上传植物却识别出是动物的结果。我们可以通过增加和调整训练的图片样本来提高识别率,减少了图片到百度服务器的传输时间和结果返回时间,如果可以将训练好的模型放到app端可以更近一步提升识别速度。
相较于程序开发,目前图片样本收集和处理仍是最耗时的工作,图像识别系统后期的研究目标就是如何更低成本、高效、准确地收集和处理图片样本,让系统更加智能化的运行。
